隨著深度學習模型在計算機視覺等領域取得卓越的成果,其安全性和可靠性也引起了廣泛的關注。 對抗樣本(Adversarial Examples) 是一種經過精心設計、對人類而言無法察覺的輸入,但卻能導致模型產生錯誤預測。這對於安全關鍵的應用,如自動駕駛、醫療診斷等,帶來了潛在的風險。今天,我們將深入探討對抗樣本的原理、生成方法,以及如何提升深度學習模型的穩健性,抵禦對抗攻擊。
對抗樣本是對原始輸入進行了微小、特定的擾動後的輸入,這些擾動通常對人類不可察覺,但能導致深度學習模型產生錯誤的預測。
提出者:Ian Goodfellow 等人在 2015 年提出。
主要思想:利用損失函數對輸入的梯度,對原始輸入進行一次性擾動。
公式: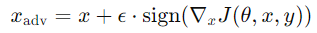
𝑥:原始輸入
𝜖:擾動幅度
𝐽:損失函數
𝜃:模型參數
𝑦:真實標籤
今天我們深入學習了對抗樣本與深度學習模型的穩健性。對抗樣本的存在揭示了深度學習模型在安全性方面的脆弱性,對於安全關鍵的應用,這是一個亟待解決的問題。我們了解了常見的對抗攻擊方法,如 FGSM、PGD、DeepFool,以及提升模型穩健性的防禦策略,如對抗訓練、梯度隱藏等。未來,隨著研究的深入,我們有望開發出更為可靠和安全的深度學習模型,推動 AI 技術的健康發展。
那我們就明天見了~掰掰~~


 iThome鐵人賽
iThome鐵人賽